I’ve produced a lot of data over the years. Some of this data is super crazy important (we’ve been working on Aztez for over 5 years now–the project must absolutely be immune to data failure). I’ve refined and clarified my thinking on handling data over the last few years, so I thought I’d do a brain dump here:
Classifying Data
I think about my data in roughly three ways:
1) Data I’ve Created
This is the precious stuff! Some of these things might be published, and potentially possible to recover in the case of failure, but most of them aren’t. If I lose this data, it’s gone, and it’s gone forever. Examples:
- Game projects (source code, assets, whole source control archives)
- Photography (surprisingly large, north of 2TB these days)
- Misc personal projects (usually small, some with big data sets)
2) Data I’ve Collected
I collect a fair amount of data! Mostly of this is just media, but sometimes it might be harder-to-come-by bits (obscure emulation sets, very old games, etc). The key point, though, is that if I did lose any of this data, I could find it again on the Internet. I’m not the sole person holding copies of it.
3) Transient Data
Everything else, basically–all the crap pooling up in a downloads directory, currently-installed games and software. All of this stuff is easily recoverable. Note that most backup strategies here are usually aimed at easing downtime and continuity in case of hardware failure, rather than preserving data.
Sources of Failure
There are roughly a couple of ways you can lose data:
1) Hardware Failure
Hard drives are mechanical. All hard drives will eventually fail–it’s just a question of two years or twenty years. I think drive failure is probably the single biggest source of failure for most people. They keep a bunch of stuff on a single hard drive, and have for years, and then one day it starts clicking/grinding/gasping and they’re in deep trouble.
2) Software Error (or user error)
Something goes awry and deletes a bunch of data. Maybe a script accidentally wipes a drive, or you delete the original copy of something and don’t realize it, or you simply make a mistake in moving/organizing/configuring your setup.
Software error can be especially nefarious, since all the hardware redundancy in the world won’t help you if deletion is permanent.
3) Catastrophic Failure
An entire system is destroyed: Theft, fire, water damage, lightning, malice (digital intruder, CryptoLocker ransomeware, etc)…
My Current Setup
Multi-Drive NAS
I keep all data, created and collected, on a multi-hard drive network attached storage system. At home I have a Synology DS1815+, and the office has a DS1515+. I wholeheartedly recommend Synology units. They’re incredibly stable, easy to expand, and have a wealth of useful software available.
They’re also kind of expensive, but if you can afford it they’re absolutely worth it. (I already wish I had ponied up the additional cash for the DS1815+ at the office, just have to have the extra bays for caching or extra storage).

I run both Synology units with two-drive redundancy (the volume can survive two simultaneous drive failures).
Other options, if you wanted to go the DIY route:
- XPEnology is a community-built version of the DSM software that runs on Synology hardware.
- unRAID is a easy-to-use, oft-recommended OS (not free, but pretty cheap). Handles uneven drive sizes very well, so a good option if you have a bunch of hardware/drives lying around already.
- FreeNAS is an open-source NAS solution. Sadly, like a lot of open source software, it’s ugly, complicated, and has a caustic community. But hey, if your goal is tinkering…
Physical Offsite Backup Cycling
I use 5TB external hard drives for offsite backups. Each Synology (home/office) has a backup drive connected. The drives themselves are inaccessible on the network; only the DSM software can touch them.
Nightly backups are performed using DSM 6’s HyperBackup. This is kind of like Apple’s Time Machine–the backups include versioned files until the disk is full. Backups are thinned to be recently dense (it keeps daily copies for a few weeks, then weekly copies for a few months, monthly copies after that, etc).
The drives are large enough to hold all created data. Every week I swap the drives between the two locations. In an absolute worse-case scenario, if either location is totally destroyed, I have backups from at most a week ago.

(Office setup–Synology and backup drive lower-left)
Digital Offsite Backups
I push nightly backups of important things into a Dropbox folder. The Synology units sync to Dropbox, which means these backups also end up in the offline external HD backups too. I don’t place 100% trust in Dropbox (or 100% trust in any one service, really).
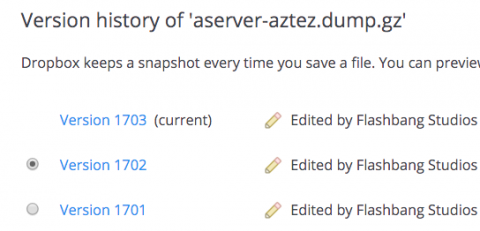
Nightly full-database Aztez source controls backups for the last 1,703 days? Sure, why not.
On my home desktop, I run Backblaze for a complete online backup of most files. Backblaze is great–$5/month per machine for unlimited storage. I have 2TB+ on Backblaze, which includes all of my personal creative projects like photography. Their recovery options including sending you a physical HD or thumb drive, too!
Continuity of Infrastructure
Some of my backups are intended to minimize downtime in case of failure:
- I keep a cloned copy of my desktop boot drive (with Carbon Copy Cloner).
- Our source control servers are VMs with data stores hosted directly from the Synology units. Even if their host fails completely, I can spin up the VM on a new host in minutes.
- VMs with local storage maintain nightly snapshot backups with 3-day retention.
- All of my Digital Ocean VPS instances make nightly database backups and weekly file backups (these get pushed into Dropbox, which then sync into the Synology, and eventually the external HD rotation).
Takeaways and Final Thoughts
Some final thoughts on things! Also a short list of what to do:
- Use the “n-1” rule for copies. If you have one copy of something, you really have zero. Aim for three copies of any and all bits you’ve created.
- Invest in a multi-drive storage system. It’s worth it.
- Bit rot is real. Run regular parity checks, or if you have a Synology, run DSM 6 (currently in beta) to utilize BTRFS, a filesystem more resilient to bit rot.
- For important data, you absolutely must have some kind of versioned backup system that can handle deletes. Hardware redundancy won’t help you if a file deletion is still a permanent deletion. Maybe this something fancy like a snapshotted backup program, or maybe it’s just a bunch of thumbdrives/HDs with your project.
- Audit your backups! If you run any kind of stat dashboard, prominently include backup age as red/green stoplights.
- Test recovery. Make sure your system backups contain what you think they contain, and that you can actually recover from them (database backups especially).
- Monitor your systems. Synology can be configured to send an email when issues arise, but do something for any/all systems. Failure-resistant systems don’t do much good if they don’t warn you when something startings to go wrong.