
For small office/home setups, 10-gigabit networking is probably a lot cheaper than you think. For larger environments, it’s certainly going to cost more, but also your IT costs should be a smaller percent relative to human/salary budgets. (If you’re in a “real” office without 10gbit, and you throw a lot of data around to network resources–get it fixed).
The Limits of Gigabit
Gigabit isn’t that fast! You’ll see ~100MB/s on network transfers. Ever needed to temporarily move a few terabytes from a computer so you could reformat it? It’s painful. Back in the days when most HDs could read/write at a little north of 100MB/s, it wasn’t as noticeable. These days, SSDs, multiple-HD arrays, and especially NVMe drives blow way past that limit.
Minimal 10gbe Setup: Direct Host-to-Host
The cheapest possible 10gbe setup is to directly link two hosts. Very commonly, this is a single server and some network attached storage device. For that, you will need:
- 10gb NIC (x2)
- Direct Attach Cable (x1)
You can find $40-50 eBay listings with two Mellanox ConnectX-2 cards (MNPA19-XTR) and DAC cable for ~$40-50. That’s everything you need.
For these sorts of direct connections, simply give each network card an IP address in a subnet different from your home network. If your internal home network is using 192.168.0.X IPs, give the cards something like 10.11.11.11 and 10.11.11.12 IPs. (The entire 10.X.Y.Z class A subnet is private). Windows/macOS/Linux/whatever will figure out routing for you.
2-port cards are just a few dollars more, if you want your storage/server to connect to up to two different hosts.
10 Gigabit Switches
The complete approach is to connect your 10-gigabit hosts directly into your network via a 10-gigabit switch. Unfortunately, this is where things get a little more expensive. I use UniFi kit, and have a USG-16-XG at home, and have been really happy with it. But that’s also $600. If you’re a small office with 5-10 people tossing around videos, photogrammetry data, or gigantic data sets, it’s absolutely worth it.
The setup here is pretty straightforward–just connect your workstation to your network per normal. My 10gbit hosts at home just have a single cable.
Other switch options:
- The Quanta LB6M24 24-port SFP+ switch is often recommended, easily available enterprise gear. It’s cheaper, at ~$280, but also LOUD, and idles north of 100W. If you have a garage networking rack at home, or a network closet far from your desks at an office, consider it.
- The MicroTik CRS317-1G-16S+RM is low power, quiet, and has 16 SFP+ cages for ~$380. Their switch lineup has a few options with 2-4 SFP+ uplinks, too, which might be good options for small setups. I don’t have experience with this switch, but I have used MicroTik gear in the past and been happy with it.
- UPDATE: Since I first wrote this article, the MikroTikCRS305-1G-4S+IN has been released. It’s a fanless, ~$125, 4-port 10gbit switch, which might be ideal for personal workstation/NAS links. They’re still a little hard to find, but I have one here and it works completely as expected (being able to power it via PoE is nice too).
Other SFP+ Cards (macOS)
The best card I’ve found for macOS is the Solarflare SFN5122F. You should be able to find them on eBay for $40. These cards perform really well–here’s macOS-to-macOS through a US-16-XG switch on an iperf3 test:
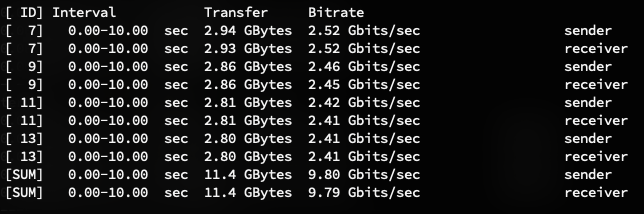
Intel networking cards are generally considered the gold standard for home use. The Intel X520-DA1 and Intel X520-DA2 are the 1- and 2-port SFP+ cards, but will cost you $80/$120 or so, respectively.
Fiber Options
SFP+ connectors are new to most home users. The world of fiber can get very confusing–there are different transceivers for different lengths of cable, cables with different wavelengths, etc. The basics are:
- “Direct Attach Cables” are copper cables with built-in transceivers. SFP+ versions can carry full 10gb just fine. Upside is price, downside is a pretty short length limit.
- Fiber optic cables are some sort of magical hollow glass. A 20m cable costs $35, and you’ll need a $20 transceiver at each end. Upside is no practical length limit, downside is cost and the inability to terminate your own ends.
Fiber is also electrically isolated and totally nonconductive. I have a fiber strand between my cable modem and my router–if an Arizona monsoon storm lands a nasty lightning strike nearby, in theory I have some extra protection from outside current.
Network Attached Storage
10gbe networking is nice when you need to copy large files around, obviously, but it also opens up a lot of options in terms of your normal file usage patterns. My main desktops no longer have any HD-based storage inside of them; what appears as local drives are backed by storage on my network. My “Photos” drive is using ~6TB–I see read speeds of 500MB/s, and there’s another ~16TB available for it.
With a large-enough HD array, you can easily saturate a 10gbe link at full 1000Mb/s read/write. This is very easy to achieve with even a small SSD-only storage array. There are two general approaches here:
Filesystem Owned by Server
Your Synology/FreeNAS/Unraid/whatever box owns the filesystem. You modify things over a file share–probably SMB, especially since macOS is deprecating AFP, but maybe NFS.
Filesystem Owned by Workstation
Your workstation owns the filesystem locally. This is probably iSCSI, where the server exposes a bunch of block storage, and your workstation/client treats it like any other block storage device–it will format however it pleases and thinks of it as a local drive. This is especially nice because things like watching files, system-level notifications of changes, etc, all work.
On my macOS desktops, I just have a .DMG disk image on a network share for my bulk storage drives. Apple doesn’t ship iSCSI support with macOS, because they have awful enterprise-related blind spots, but there are a few 3rd-party options. I decided to use DMG since it’s built-in, and those mounts still appear as external drives (especially important for me with BackBlaze and my Photos drive).
What About Laptops?
Well! If you absolutely must get a laptop on your 10gbe network, the easiest approach is an external Thunderbolt enclosure. Thunderbolt basically connects directly to your PCIe lanes, so you can drop any old PCIe card in there (not just GPUs). This $200 enclosure works great for non-GPU cards.
Thunderbolt 3 enclosures are backwards compatible on macOS, from something like 10.12.6 onwards. This compatibility is an Apple-specific thing, so I’m not sure where things lie with Thunderbolt 2 laptops and Windows. If you have a Thunderbolt 2 MBP, and are using a Thunderbolt 3 enclosure, you’ll also need this adapter and a Thunderbolt 2 cable. Ouch. You could also just get a Thunderbolt 2 enclosure, but might as well get something that will be useful for awhile yet.
Why Not Cat5e/RJ45?
I haven’t recommended Cat5e/Cat6 stuff here for a few reasons. Primarily, it’s far more expensive and hard to come by. You’ll probably have to buy new equipment, which will cost a lot more, since SFP+ has been the preferred enterprise format for years. It’s also slightly higher power consumption across the board (NICs/switches both).
If you’re already in an office space with a LOT of cat5e/cat6 cable already run through your walls, it might be worth using. I just don’t have experience with it and can’t really recommend anything.
Why Not Gigabit Link Aggregation?
There are a multitude of ways to aggregate >1 network ports. Many consumer NAS devices have 4 gigabit ports, for instance. The short answer is that single network streams are still limited to gigabit speeds. This is a great option for something like a NAS that wants to show up with the network with IP over 4 ethernet ports. Four clients could each be pulling 100MB/s from the server, but an individual client will still be limited to 100MB/s (even if they are aggregating multiple ports on their end too).
Questions?
I am by no means a networking expert, but feel free to ask any questions! Either over email (mwegner at that Google email service), or here in the comments. I know–leaving comments on a blog is so mid-200s–but at least they’ll stick around for when someone finds this article a year from now.